
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Spark
- 블록체인
- data discovery
- databricks
- GPT
- backend
- Ai
- frontend
- bricksassistant
- 디스코드
- crwaling
- blockchain
- MLFlow
- airflow
- 챗봇
- ChatGPT
- discord
- 디스코드봇
- 디스코드챗봇
- video understanding
- Rust
- embodied ai
- vln
- Golang
- vision-language navigation
- datahub
- s3
- embodied
- bitcoin
- Hexagonal Architecture
- Today
- Total
BRICKSTUDY
brickstudy 공용 데이터 환경 구축기 - 1 본문
Introduction
현재 각 프로젝트에 사용될 데이터를 수집하고 관리하는 업무를 맡고 있는데요.
프로젝트가 기획되고 있는 현재 시점에서 본격적인 데이터 수집에 앞서 수집 플랫폼의 구조를 잡아가고 있습니다. 데이터가 저장되는 구조, 현재까지 개발된 사항, 이 과정에서 고민했던 내용들을 공유하고자 합니다.
Background
실제 현업에서는 데이터의 형태, 양, 수집되는 소스가 정말 다양하고 이를 관리하기 위한 여러 DE 전략을 취하고 있는데요. 메달리온 아키텍처는 그 중 데이터를 비즈니스 유저에게 안정적으로 배달하기 위해 단계들을 만들고 이를 템플릿화해서 표준으로 제안하는 것입니다. 저희 역시 이 구조를 적용하여 데이터 수집 플랫폼을 갖춰두려고 하기 때문에, 이 개념을 공유하고자 합니다.
Medallion Architecture
- Data Lakehouse 환경에서 데이터의 품질과 구조를 점진적으로 개선하는 계층화하여(bronze, silver, gold) 데이터를 저장 및 처리 하는 아키텍처
- Data Lake(ELT)의 유연성과 Data Warehouse(ETL)의 구조적 강점을 결합하여, 데이터의 신뢰성, 가독성, 분석 용이성을 극대화할 수 있다.
- Databricks에서 처음으로 제안되었고, Microsoft Fabric에 적용되어있다.
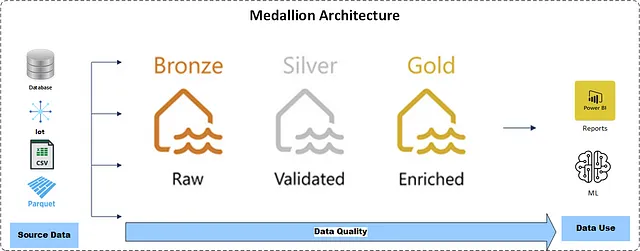
Layer - bronze, silver, gold
bronze - raw data
- 다양한 외부 소스에서 발생한 모든 데이터의 initial landing zone.
- 로드된 날짜・시간, process id와 같은 메타데이터로 소스 시스템으로부터의 원본 상태를 그대로 적재한다.
silver - cleansed data
- 분석 목적으로 최소한으로 가공된 cleansed, verified 데이터
- 데이터 클렌징, 중복 제거, 오류 수정, 포맷 표준화 등
- bronze layer의 데이터를 통합하여 일관성 있는 형식으로 변환하고, 이를 통해 데이터 간의 관계를 정의하고 통합된 뷰를 제공한다.
- 중간 단계의 분석, 데이터 탐색 및 준비 작업에 사용된다.
gold - business-level data
- Silver 레이어애서 정제된 데이터를 더욱 가공하여 최종 비즈니스 목적 최적화된 형태로 데이터를 가공해둔다.
- dimensional model, star schema 형태의 데이터 모델을 갖추고있다.
- 빠른 응답 시간을 필요로 하는 Business Intelligence 및 리포팅 도구에 적합하여 리포트 작성, 대시보드, 데이터 시각화, 고급 분석에 사용된다.

Main Content
Development progress - Data Extracting module
현재 검색 키워드 및 검색 대상 플랫폼을 쿼리 인자로 naverAPI를 통해 데이터를 수집하는 모듈, AWS sdk를 통해 S3에 데이터를 적재하는 모듈을 개발했습니다. 해당 모듈을 통해 데이터를 수집 및 적재하는 airflow task가 스케줄링됩니다.

가독성, 재사용성 및 확장성이 높은 코드를 안정적으로 운영하고자 TDD 개발을 하고 있고, 데이터 클래스를 정의하여 API request/respond 인자들을 관리했습니다.


dataclass는 코드 중복을 최소화하고 코드 안정성을 높히는 것을 목적으로 도입했습니다. API를 사용하기 위해선 사용 표준을 준수해야하는데 dataclass를 통해 데이터 구조를 명확하게 정의해두어 파라미터가 무엇인지 명확하게 확인할 수 있고, 타입 오류, 파라미터 값 오류를 방지할 수 있기 때문입니다. 클래스마다 인자를 반복적으로 명명할 필요가 없어 향후 개발 시 코드 재사용성이 높아지는 효과 또한 있습니다.
현재 유닛 테스트코드 역시 바람직한 테스트코드라 보기는 어려운데요. 실제 s3에 데이터를 put하고 read하여 데이터 정합성을 확인하는 방식이기 때문입니다. 따라서
1. s3에 데이터 실제 업로드 -> 테스트 반복적으로 수행되면서 과금, 불필요한 network latency, 테스트 이후 데이터 정리 필요
2. 테스트코드 자체에 대한 신뢰성 문제 -> 인터넷 연결, aws 문제 등 외부 환경에 의존성 존재
와 같은 문제가 존재합니다.
이에 mocking을 통해 위의 문제를 해결하는 것이 필요한데, aws sdk 관련 테스트를 위한 도구로 moto, stubber가 있습니다. aws 서비스의 api를 mocking하는 라이브러리와 api 호출 응답을 mocking하는 라이브러리인데요. 관련 자세한 설명 및 적용은 다음 공유회에 나눠보겠습니다.

Our Medallion
현재 저희의 main destination stoarge로 S3를 사용하고 있습니다. S3 내에 아래 이미지와 같이 공용 버킷 안에 각 프로젝트의 Data Lakehouse가 존재하고, 각 프로젝트의 DL에 메달리온 아키텍처를 적용하고 있습니다.

bronze/silver/gold 레이어를 구분하는 명확한 기준이 없고 비즈니스 목적과 상황에 따라 의사결정을 해야합니다. 툴을 정하는건 상황에 따라 어느정도의 “답”이 존재하지만, 레이어와 각 레이어에 적재할 데이터를 정하는건 데이터를 이해하고 상황을 고려하여 가장 최선일 것 같은 방안을 선택하는게 필요합니다.
현재 공유하고자 하는 논의 사항도 이와 같은 맥락입니다. 각 레이어에 어떤 데이터를 쌓아올릴지는 향후 데이터가 본격적으로 수집되고 더 논의하겠지만 그 전에 a. 프로젝트>레이어 구조로 경로, b. 레이어>프로젝트 구조로 경로 둘 중 어느 것이 더 적절할지를 상정합니다.
a. {레이어} / {프로젝트} / {매체분류} / file
- 프로젝트 별로 medallion 구조를 적용하여 데이터 수집, 처리 storage를 만든다.
- 각 프로젝트의 데이터 특성이 다르고 이를 명확하게 구분해두는것이 관리에 용이
b. {프로젝트} / {레이어} / {매체분류} / file
- 스터디 자체 Data Lakehouse를 만들고 각 프로젝트의 데이터를 일종의 카테고리처럼 사용
- 프로젝트 간 데이터 사용 활성화
'Data' 카테고리의 다른 글
| [viral 탐지 프로젝트] 데이터 파이프라인 구축기 #1 (1) | 2024.09.22 |
|---|---|
| AWS lambda를 활용한 S3 적재된 데이터 카탈로그 확인 도구 개발기 (2) | 2024.08.08 |
| spark local 환경구축하기 (2) | 2024.07.21 |
| Spark, Airflow, mlflow, databricks Let's go! (1) | 2024.07.21 |
| [Spark] 데이터 엔지니어링에 테스트 코드가 필요한가? (1) | 2024.07.20 |


